Some thoughts on about coding, AI, and where we go from here
Before I get started writing this article, a few notes:
This was not written with AI, but I did use AI to help with describing concepts better (and using actual terminology). This is a braindump of thoughts about AI I’ve had for 1-2 years.
This will be a messy and long blogpost. Please, feel free to summarize it with AI actually! I’m not the best writer, my grammar will get worse as I keep writing, and I tend to write more verbosely.
I am not someone who writes frequently, I go slow when building things, I take my time, and I am certainly not a known figure who is the best person alive at engineering.
But I wanted to throw my opinion into the wild for anyone who wants to read this.
Background
I’ve been writing software since 2016 - when I was 13 years old. I have loved technology since I was a kid.
I got my start at iD Tech Camp and self-taught myself in middle and high school. I went to college from 2020-2024, graduating just as models like GPT-3.5 were coming out. These models were useful, but nothing groundbreaking. I’ve been employed since 2022 in software engineering - working full-time over summers, part-time during school, then back to full-time after 2024.
I consider myself in an odd position being so young but having a relatively expansive background and having coded pre-AI for almost 8-9 years, and having done so professionally for about 2-3 years before the AI boom.
It’s worth noting that I am, just a normal engineer I guess? As the title says - I work at a good software engineering company where we tackle genuinely interesting problems, but it’s not FAANG level. I’m not constantly out on X or the internet posting my opinions, but I observe what other folks say. These are my thoughts for someone who’s not fully on the AI hype train but has been watching it.
Where I stand on AI
With any new tool or framework, I’m always a mild skeptic, but I like to try something new and see if it works if I really think it will improve my code or projects in a meaningful way. At work, I use AI every day, because I have to - I wouldn’t have a job if I didn’t. At home with my projects, I’ve been using AI a bit more, but since most of my projects I work on were made pre-AI, I still code by hand.
At work, we had the option between GitHub Copilot and Cursor for some time (I opted for GitHub Copilot), then switched to Claude in April. GitHub Copilot was…interesting, Claude is better (but not infallible), but I’ll talk about this a lot more.
I have mixed feelings about AI. On the one hand, it’s a genuinely powerful tool that is changing the world right now. It can empower people to become "10x engineers”, or at least materially increase velocity. It’s fantastic for using as a rubber duck or to learn new concepts, and as a search engine, it’s surprisingly good. It empowers people to learn new topics just on a $20/mo subscription that otherwise might be out of reach. It can make you a better writer, coder, person even, if used right. And AI, when used correctly, is a great tool for solving incredibly hard problems.
On the other hand, we’re still grasping a lot of the downsides of AI, and it’s making a huge mess of our world. A large portion of our economy is propped up by AI - with billions being poured into it. AI is continuing to exacerbate an already bad wealth inequality in the US and globally. Personal computing, hobby electronics, and ordinary people are affected by RAM/storage price increases because AI is gobbling up the worlds memory supply. And AI is being pushed down so hard on the general population when I think a lot of people just…didn’t ask for it. Our social media platforms are full of AI slop, open source projects are closing their doors due to AI contributions, and I’ve noticed we’ve become a less trustworthy world because of AI.
This is a nuanced conversation! I’m sure the AI enthusiasts will disagree with me, and this article generally tilts more towards AI skeptics, but I also use AI regularly and see the benefits. I’m not dragging my feet, but I think we ought to use a little care and discipline about AI.
AI made a big shift in late 2025, and it is real
Back in late October 2025 (or around there), we got models such as Sonnet 4.5 and GPT 5, and they genuinely changed the landscape of AI, especially in software engineering. As we got Sonnet 4.6 and further iterations to GPT, like 5.1 and 5.2 towards the end of 2025 and into early 2026, we clearly entered a new time period for how good these models were getting.
Before October 2025, we used GitHub Copilot at work with GPT 4.5/4o and maybe Sonnet/Opus 4. These models were improving over time, but not by huge strides. I used them at work occasionally, but found that they tended towards being less helpful than more helpful. In a limited context, they worked alright, but on larger projects, fell apart and made very odd decisions if you didn’t guide it correctly. With AI, sometimes it would take longer to do a task with it than without it - I was very 50/50 on my use of it at work.
I remember having a teammate at work who used Cursor extensively during this period and put up PRs with very unpolished code straight out of AI, and these code reviews were painful. Strange design decisions, odd naming conventions, 6 levels of indentation, you get the gist. Code reviews genuinely took longer on code that was AI generated versus hand-typed.
After October 2025, a shift began to happen, and models started getting pretty good at their job. GPT 5, then 5.1 and 5.2 (along with Sonnet/Opus 4.5) were shifts were the AI was getting good enough, and the harnesses around them developed that they could run on their own and iterate by themselves. January/February 2026 was the turning point in AI, especially at work, as it genuinely got faster to write code with AI than without it, and it made fewer mistakes. With MCP, skills, the concept of subagents, tool calling, and harnesses proliferating, you could no longer ignore AI.
And we certainly can’t now. Since 2024, the world has changed rapidly around AI. Too rapidly, I’d even argue.
We still haven’t gotten a hold on AI
I’ll start this article by saying that AI is incredibly new. Every time I see people professionally talking about concepts such as agentic development, MCP, skills, prompting, AGENTS.md files, I have to chuckle a little bit. I mean, 6 months ago, half of this shit didn’t exist (aside from MCP - that’s been around for a year now). We’re still grasping AI as we go and attempting to pass it off as professional knowledge.
Now, I agree, things are stabilizing and we are getting more of a grasp on how AI works. General concepts about prompting and agent files remain in place today. But AI is a non-deterministic machine - it will always do something weird, and definitely never trust it to do the same thing twice in exactly the same way (without prompting the shit out of it). Stuff like design loops, spec-driven development, research-plan-execute workflows (okay, I admit, this is Claude Code plan mode, but the more fleshed out skills is what I’m referencing), then we learn that telling the AI to be an expert in an area actually works the best.
Some stuff has solidified - agent files (but as to how you format the content in them…that’s another can of worms), general prompt concepts, that stuff is steady. But we’re all new to this AI world. Let’s stop pretending that when we share this information with each other that we are preaching the choir, because in 3 months, literally anything can change.
Markdown becoming turing complete is hilarious
Agents and skills have made Markdown turing complete, please do not argue with me. I think it is funny. That’s all for this section.
Multi-agent workflows, their cognitive load, trusting AI, and how far you want to detach yourself from the system
Online (and at work), I’ve heard of people juggling numerous AI agents simultaneously. Dozens of agents on their own, completing a well-scoped task, pushing code, increasing velocity by amounts that are unheard of!
To that end - there’s an inflection point I think engineers have to grapple with. Either you let dozens of agents run wild building you software where you (likely) have no clue about how it really works, or you have a couple agents running simultaneously with some babysitting where at least you get an idea of what’s going on, or it’s 1 agent and a lot of back and forth with much greater understanding.
Before AI, much of your understanding of how a codebase worked by having to actually write the code, and for onboarding to a codebase, working with a specific chunk of the codebase. And that was very true for all my projects and at work. You’re able to develop such an intricate model of how the code works, flows, and if something goes wrong, probably pinpoint exactly where it broke.
You can probably remember this from school days too - teachers always recommended writing down notes, summarizes, rather than reading them, because your brain does more work to understand the concept, then write it down. And you catch yourself when there’s a misunderstanding, reinforcing that knowledge.
With AI, full stop, this has been out the window if you’re not writing the code. Even if you read AI generated code, you will not understand code the same way as if you wrote it. I’d argue you will never understand it as well.
It seems like most people have accepted that we have lost this deeper understanding to increase the material velocity of how much code we can produce. A lot of people approximate this to when we went from assembly to languages like C, then languages like Python, a level of abstraction was lost, and a more general understanding was formed. Now, the next step is that we’re going from code to English or a level “beyond the code”. I will talk more about how I think English is, in fact, not the next level we need to abstract to.
Writing code was a proxy to understanding the system as a whole
We’ve gotten to a point where AI, given a detailed enough specification, can produce code that works pretty well, is readable, looks professional, is well documented, and is…completely fine (although there is something to be said about how AI code has zero imperfections and looks so…sterile). A lot of people have pointed out that this is the first productivity gain from AI - it writes code that is mostly correct on the first try, if you give it a testing & linting system, maybe a few tries.
And yeah, I agree. At work, I give Claude a prompt for what I want, well scoped, with nuances defined, and you get to this really odd point. You know what the code is going to do, you’ve thought about the design, maybe in your head some edge cases or quirks to avoid. But it’s never the same understanding as writing the code yourself. That’s the first layer of detachment with AI coding, and I think most of us have accepted it at this point. At least at work I have. Maybe not personally.
I think sometimes it’s easier to detach at this level from frontend code compared to backend code. But I also say this knowing that a lot of my frontends aren’t where the business logic lies. For web apps where it is the entire system, or it’s client-side only, then this does not apply.
I also acknowledge that in a large enough system, it gets harder for a human to understand the entire system in detail, at some point you lose granularity unless it is documented somewhere.
So, how much do you trust AI? How much do you want to be removed from the system?
For some people, they trust AI agents a lot. Maybe they don’t mind being removed from the code itself, they’re okay with a high-level knowledge of what’s going on under the hood. There’s definitely a lot of people who point Claude at a Jira ticket, tell it to implement it, and a few hours later, it’s done. That is the velocity increase I think a lot of people expect from AI.
And I have no problem with it. For smaller scoped problems with a clear end goal, it’s the bread and meat of a LLM. “Make this small feature or small change, write tests, write a PR”, and you get a diff you can actually review.
The thing is…AI can (and will) happily present you code that looks right, quacks right, but can have fundamental logic issues that take twice as long to dig into.
We’re in a post-review world and everything is a blur
One of my coworkers who works in QA says we’re in a post review world. Given the speed at which AI can spit out code, it makes zero sense to handicap yourself with code reviews because then humans are the bottleneck. I agree somewhat with this point, but it depends wildly on the company you work at. I will share with you the experiences from my company.
Back in ye olden days before AI, code review by hand generally caught most bugs, because you operated on a system of trusting your coworkers, and that incorrect code often had a smell to it which prompted you to dig deeper and find more issues. This worked a lot of the time - I was known as the guy on my team to leave occasionally scathing PR reviews pointing out dozens of issues with your code.
AI has wiped this entire concept out the window because all the code AI generates looks correct on the surface. Nothing looks “off” in the same way, there’s no obvious stink, and the AI usually leaves comments justifying its behavior with well-named variables. To find any stink, you have to dig deep, which increases code review times for every single review. AI is known to confidently present false information, and it surely does that with bad code implementations and designs.
Especially with trying to understand function flows and design, it’s all so sterile with such perfect function names and formatting that I find AI code easily 2x harder to mentally understand compared to human-written code. AI loves to leave comments in places where code can explain itself, be silent where it needs to explain itself, or write an 8-line comment about some bug that it had to go back to 4 times to make sure it will never fuck up again. Isn’t CLAUDE.md for that, by the way?
And do not even talk to me about diffs exceeding >1,000 lines that you can oh-so-easily pump out with AI. Attempting to review those is almost a pointless exercise that basically requires you to blindly trust whoever drove the AI to steer it in the right direction.
The issue is that when the motto is “Ship fast!”, and good code reviews universally take longer with AI-generated code, and that there’s only so many hours of work, and that I’m not getting paid more to spend an extra 2 hours a day looking at AI generated code…something’s gotta go. The combination of the desire to develop more features in a shorter time period while not adding buffer for doing the extra code review is dangerous - at my job, it has led to buggy code going out into production, because we do not have time to review code in-depth. And then what, I have to trust Copilot code reviews? The code review skill in Claude Code? Trust the AI that made the mistake in the first place?
There’s still a lot to be figured out with how we do code review in an AI world, and at least where I work hasn’t instituted any sort of mandate to spend longer on code reviews, and anecdotally, it seems people spend less time doing code review, even though there’s more code to review.
Cognitive load with AI has gone up wildly, context switching is still expensive
Another thing I’ve noticed with AI is that the cognitive load of using it has gone up tremendously because context switching is insanely expensive.
When Claude Code first hit our company, I was running at least 4 simultaneous agents in tmux getting stuff done. But the cognitive load was incredibly high - because for all these sessions, I wanted to review what it’s outputting (I don’t fully trust AI, and after all, my name is on this), maybe this session was going off the rails a bit and I wanted to steer it now to waste less time, then this other session is running into an issue, oh wait, the other session doesn’t know this one peculiarity and is wasting time, and then that’s when it hit.
Context switching still has the same cost, and when you’re running multiple agents, every time you go back to an agent to do something - refine an output, look at a PR it made, or guide it with an error, you have to switch context back to that task and what’s around it. It is an immense cognitive load that made me feel much more burned out at the end of the day. And then I stopped doing it at work to be frank.
I guess I’ve landed here: I usually have 2-3 Claude Code panes in tmux at the same time (usually 2). Any more and I realize that all the context switching is shedding crucial understanding of the task and is overloading myself. In this case, it’s a happy medium, I get the productivity bonus of AI but I’m still pretty close to the code and have a good (enough) understanding of what’s happening, and I can maintain this for longer periods of time.
The prompting gap, customizing AI, and nuance
I guess this brings me to my next point - AI prompting. I have wildly mixed thoughts about prompting AI and how it brings different results, best practices, what to do, so bear with me.
With things such as Claude Code, they are marketed on some premise that you prompt it, give it a problem you’re having, and it goes and builds it. For small features, as I mentioned earlier, that’s fine.
For bigger issues…prompting is such a nightmare sometimes. Many times when I’ve been using Claude, I can’t think of a certain nuance or decision I need to make in the future because it hasn’t hit me yet. Sure, I can write longer prompts and eventually uncover the nuances…but I might as well go do it myself then!
AI models are largely trained for user satisfaction I believe. They want to get the job done for you in a way that you will not yell at them or have a bad experience. I remember seeing this manifest in how earlier AI models would hilariously put a huge try/except block around 100+ lines of code in Python, even simple arithmetic, because less experienced developers wouldn’t have issues. Even the latest models sometimes will do this, even though one of the first lessons of Python is to scope your exceptions as best as you can!
The default behaviors of AI are incredibly odd and backwards sometimes. I waste so much time every day telling AI painfully obvious things, or nuances that, while in my head, could be read from code. For instance, at work, I was letting Claude write up documentation about our OTEL setup. One nuance is that the auto-instrumentor for the Kafka library is turned off because we manually add a span to add extra fields to it. You can pick this up from the code. Claude Fable 5, yes, Fable 5, decided that the documentation is a good place to make a high and mighty suggestion about how this code should be turned off, it is moot, and that it adds no value. It never picked up on that we wrap publish spans manually because we want to add fields to those spans like the message type, and baggage for approximate Kafka latency. That is what I mean about AI lacking nuance.
To Claude’s credit, yes, the Kafka auto-instrumentor should go away. But then maybe ask me if I’d like a Jira ticket about that, because that would actually be useful.
Nuance man, nuance. For how impressive AI is these days, the lack of nuance in so many situations is astounding, and it’s what truly prevents me from fully trusting AI with anything. I trust it less than a junior developer sometimes. For everyone saying “just prompt it better” - before AI, nuance came up as you were writing code. Given the context of a ticket, seeing how some approaches might not work while I’m writing it, perhaps the goalpost needing to evolve into a final shape, it was part of the code writing process. Now, you have to frontload all of that to prompt the AI with every teeny tiny little bit of nuance it needs to do the job correctly. But at some point, frontloading that into a prompt, then letting AI work, might take longer than doing it myself and letting AI do a “grill my code” pass over my work for optimization!
I’ve recently been using auto-mode for Claude, but in every single prompt, I always have to tell it “make a remote branch, commit, make a PR on GitHub”, because sometimes it won’t make a remote branch. Sometimes it tries to commit on main. I know there are memories so AI can understand my usual style and preferences, but sometimes I don’t want the agent to make a PR, especially if it’s something experimental or in a draft state, so I have to manually specify my intentions per prompt, which wastes a lot of time. It would be tremendous if I could prompt AI with something like “This is an experimental draft”, and it knew to make a draft PR on GitHub.
Sometimes AI will happily find bugs for me in my codebase that are genuine bugs and that should be fixed, and fix it for me, and it feels like magic when it happens…10% of the time. The remaining 90% of the time, AI is bending over backwards jumping up and down at me about some bug it thinks is critical when, in reality, it’s not.
I’ve let Claude Code (using Sonnet 4.6) work on my DIY weather station codebase a decent bit, and recently it was badgering the shit out of me about how, when the station reboots and reads from the local database, if the previous rainfall rate was < 1 inch, because I was clamping a float value as an integer, it would be 0. And it would not let up about this. Yes, it’s a bug. But it’s a bug at initialization time, in a program where, get this, you can infer from the entrypoint that it’s a long-running program. And it’s not always raining at reboot time. Maybe Claude can infer that since this code is for a weather station, maybe it’s outside? Maybe the chance of a reboot occurring in the rain is comically low? And pass it off as a little thing to note and fix.
That is one out of many, many times Claude has suggested such low-level fixes to me that, if you had nuance, you’d realize it’s not that important, or there’s another system designed to catch those errors. I get it, these AI companies want their models to perform well in a variety of scenarios, and my scenario is unique to me. And that I should write this in CLAUDE.md for this to never happen. But then I’m burning time writing that file with all my intuitions that could change at any moment. But then CLAUDE.md doesn’t get updated, someone forgets, we didn’t instruct Claude in CLAUDE.md to update it’s own CLAUDE.md file when something changes (this happened at work recently, Claude even said “I updated the CLAUDE.md file because it was so out of date), like, why aren’t you updating your own documentation when you need to? Why does this need to be made explicit?
Humans having nuance, intuition, and good context about a situation is what gives us a gigantic leg up over LLMs. I understand you need to give context to an AI to make it perform well, but if I really need to give it a braindump so it doesn’t fuck up as often, then where is the time savings in using AI?
LLMs love to write shitty, verbose code
For a more clerical example of the above, I asked Claude to fix an issue on the OctoCam Frontend where streaming videos from the long-term archive was slow, the entire response got buffered at once, and it worked poorly on slow connections. Initially, Claude proposed this fix:
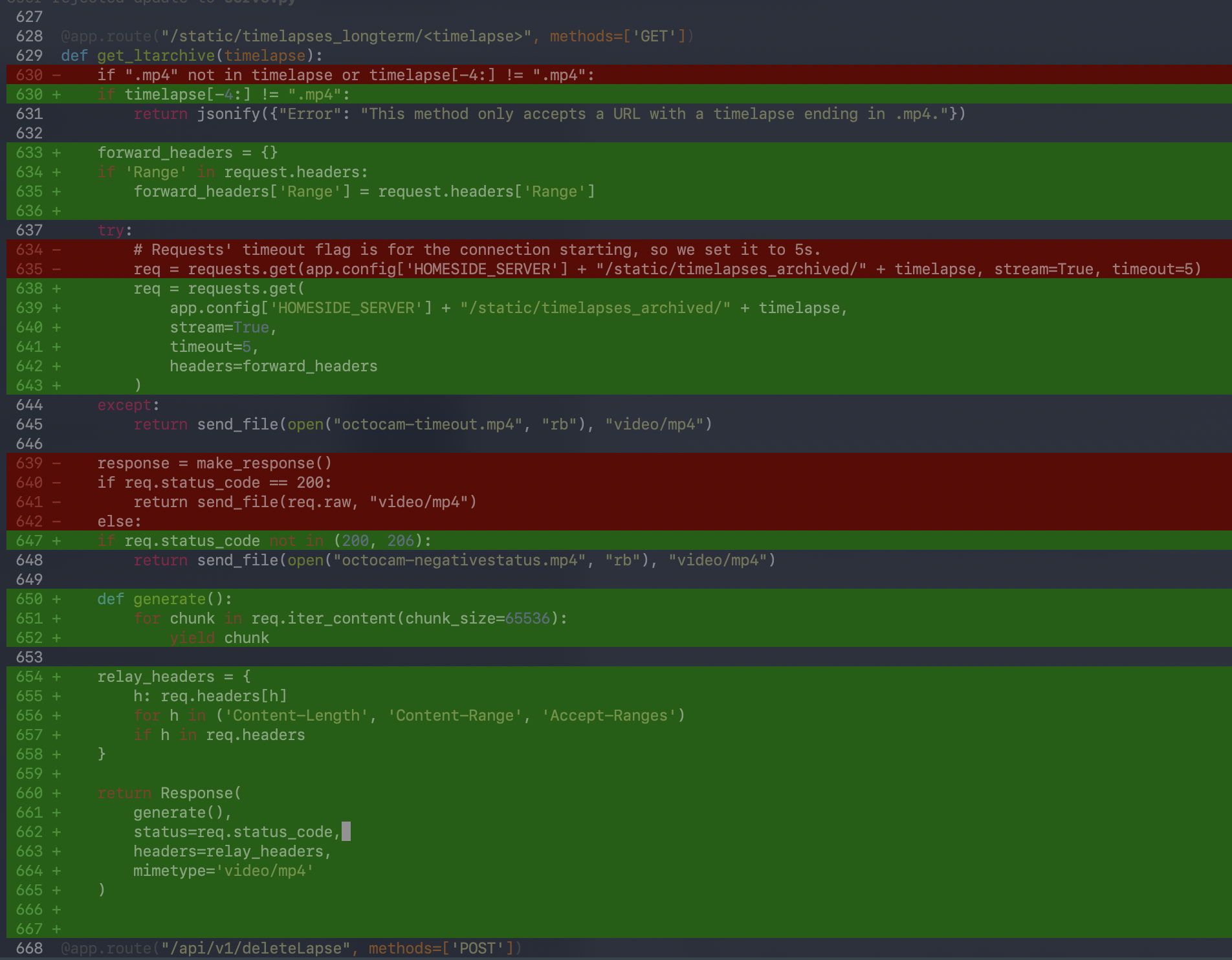
From a glance, the code looks fine. But dig a little deeper…single-use variables, statements that could be inlined, a needlessly complex dictionary comprehension, that’s where the code stink really lies! It’s too verbose!
It then took almost 7 turns to get Claude to finally generate code that actually looked sharp, precise, and readable.
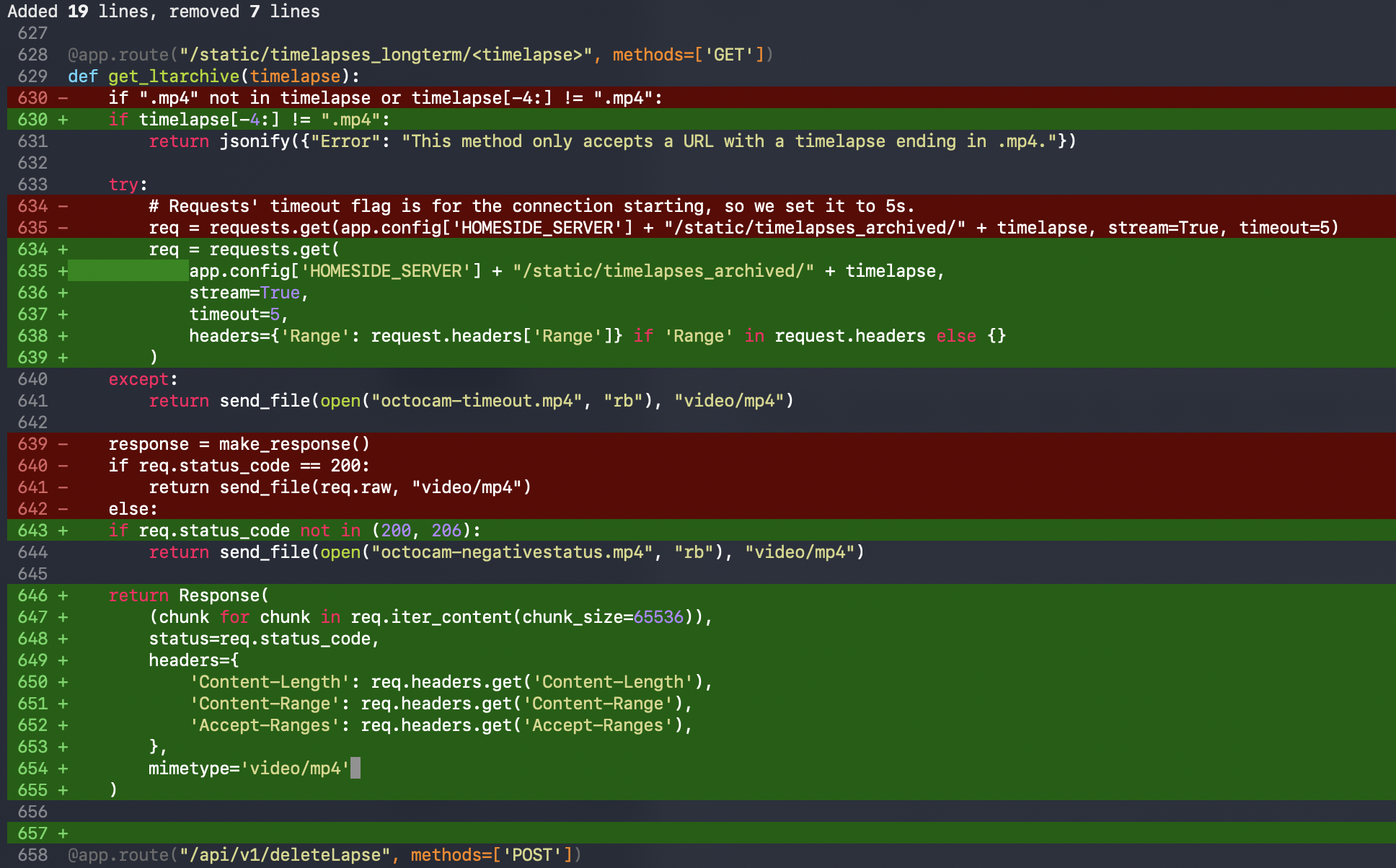
But that’s the thing. It took 7 tries. 7 tries! And even at the 7th try, it still decided to delete that comment about the timeout flag for…who fucking knows why, and name the response req!
This code does the same thing, but the diff is much more readable, because it’s expression-oriented, using strong idioms, and it looks Pythonic. This is code I want in my codebase, this is how I coded back before AI: do it surgically, cleanly, and simply. Keep it simple stupid and YAGNI are powerful idioms that still have merits to this day!
This is what I mean about LLMs having no immediate code stink, but when you dig in, a lot of code stink. Each turn was me asking Claude to:
Generate the response headers dictionary in a static manner, you’ll only ever need 3. Why is there a separate variable and comprehension to generate that?
Inline generate() as part of the response, it’s never getting used elesewhere
Use a ternary on the range headers
And reject other dumb styling choices Claude was making (like adding walrus operators doing the dict comprehension)
Tangent: Attempting to defend my coding style
I’m sure someone reading this will probably complain about my coding style and why it is bad - so let me present you with why I code the way I do. When writing my code, I attempt to optimize for single-shot readability: how much of this code can I understand on a first pass. Extra lines, unnecessary loops, non-obvious variable names, they all add overhead to your brain reading the code and distract from the final understanding of the code, taking multiple loops to come to an understanding.
Take the generate() function for example. Some people will think it’s better to use it. Personally - I don’t. I feel like on a Response class, the first argument that isn’t a kwarg is probably the response body. And the final revision bluntly states inline that the response is generated by returning chunks of 65,536 bytes from the response from the OctoCam backend. Before, I would’ve had to frontload generate(), then remember what it does (or look back up).
On the forward headers - it’s just too busy. Three lines to do one adds extra noise when reading the code, and ternaries are easy to understand when written well (big emphasis on written well).
The goal? If my brain is at reduced operating capacity - maybe I’m tired, or I just woke up - I should be able to get a general understanding of what my code does and be able to make a small patch in real time, until I can make a better patch when my brain is fully awake again. While that may sound silly for personal projects, imagine if you’re on call and, oops, Claude wrote everything and it’s impossible to understand what the fuck is going on without Claude. But that’s for the next section.
Why can’t these bots have sensible defaults built-in? I get that everyone’s stylistic preferences are different, and I am not claiming that mine are better, but the final revision follows the Zen of Python a lot closer than the first revision, and the last time I checked…when writing Python code, you should at least try to follow the Zen of Python. That’s kind of the whole shtick of Python, readability. The first revision, in my opinion, is a lot harder to understand at a glance compared to the final revision. It also feels like I’m teaching Claude good coding skills like a L1 engineer, which checks out as to why Claude usually feels like a L1 engineer.
Here’s the thing though. For a surgical edit on a personal project, I can afford to spend time with Claude and coax it to do a better job with how it writes code, because it’s my project, my code, my rules. But do you think I have time to do this at work with diffs that are much larger than this, and where my velocity is expected to be increased? Absolutely the fuck not. Sure - skills like Ponytail exist. Your personal preferences via memories also exist. But they only bridge the gap - not fully close it - because these LLMs are trained on safer code for better user satisfaction.
And I’d actually like for smaller diffs because that’s less output tokens! I think we’re going to end up with a lot of very verbose, yet ultimately harder to read code from this AI era.
Humans should be kept in the loop somewhere, ideally at System Design (aka Spec-Driven Design is a bad idea in my opinion)
At work, I switched teams to ML because I had been on my previous team for 4 years, and I felt like I hit a growth cap of being the most senior and technically sane person on the team (which should not happen at 23). I was, for what it’s worth, basically technically leading the team.
At the very beginning, the new manager for that team asked me about potentially reviewing new system designs for stuff I had worked on for a while. In short, we hosted virtual devices and we switched to a 1:1 mapping of a virtual device to a Kubernetes pod. It was done because we were prioritizing reliability, but for load tests, yeah, it costs a lot to scale it up.
So the proposal was to go back to having multiple devices per pod, but this approach has so much nuance to it. How do you load balance correctly? Recover state? What happens when Karpenter evicts your pod? How many devices do you put on a pod? Load tests make 10,000 virtual devices, but at other times, it’s 300. If Karpenter evicts one pod, 33% of the fleet goes down! It’s a genuinely complicated distributing systems question - stateless virtual devices with as little downtime as possible.
When I was in charge of architecting the new Kubernetes-based approach, I had a lot of factors to consider, reliability being keen amongst them, and 1:1 via Kubernetes won because it was stable, relatively simple, and we had a reliability PR nightmare that needed to be solved. And it was reliable. Not perfect, but reliable. Because we put nuance, care, and thought into the design, and when we implemented it, there was no stone unturned, and we were able to deploy it relatively easily. Everyone on the team knew pretty much how it worked because of extensive discussions and documentation.
So imagine my fear when the new manager DM’d me on Slack with a draft spec and it’s…entirely AI generated output. On the surface, the AI was making good points, it seemed like it had a good design, but here’s the thing - when AI is doing system design, it is making an output. It might clue you into its chain of thought…but that’s literally 90% of system design! The last 10% is writing the fucking document! I want to know your chain of thought and how you evaluated the options and chose this one!
Even when the manager said “yeah, this was shit”, as kindly as I could, said that I’m not reviewing any more designs, the team is going in a new direction, and I don’t think my prior experience and knowledge is valuable. Of course it’s not valuable when you’re asking AI to design everything for you!
Doing system design mostly/entirely with AI should be and, in my opinion, is a red flag. I talked earlier about how AI can produce output that looks reasonably correct on the surface, but when you dig just a teeny tiny bit deeper, you realize it’s full of shit. For code, the consequences are that you either run a code review skill so issues are flagged, you ask the AI “are you sure about this?”, then it goes, “You’re absolutely right!” (wow, thanks, for the 50th time today you’ve said that), and that’s that. For system design, the consequences are much more severe. You’re instinctively relying on an AI to do fundamental design work that will last for years, trusting that the output it gave you balanced all the trade-offs and constraints with your setup, and the minute you start implementing it, you’re largely locked into said design. And because you relied on AI to do the initial design work, you’re probably going to delegate AI to do future design work, coding work, finding issues, because you didn’t gain the fundamental understanding of your system because you didn’t design it yourself. You may have reviewed the documentation, approved it, and know what’s going on, but do you really know what’s going on?
I’m sure there are exceptions to the rule. I’m sure people read AI design documentation and can make a very good mental model in their head. But truth be told, the generation effect is a bitch and is widely studied! The venn diagram of people overlapping on “using spec-driven development” and “eagerness to read a design document in-depth to fully gain a mental model” I’d argue is relatively thin! Thinner as I tend to think that reading AI-generated design documents are so much harder because they are incredibly verbose and fluffed with detail. When humans write these documents, we’re limited by our typing speed and how much we can say, we naturally try to leave out bits that aren’t important. And just on my opinion, reading text a human wrote is so, so much easier to read than AI-generated text.
Anyway, having this mental model of a system is so crucial down the line in my opinion, especially when something happens in your system, users are impacted by downtime, Claude is down because it can’t manage two 9s most of the time, nobody on your team really knows what’s going on, and now you have to wait for Claude to think with high effort to get a bug fix out. If only your team had an actual idea of the system design and where the bug existed in your codebase so it could get fixed faster! It’s almost like we did this before AI. I still do system design manually when I can, even at work. Nothing can beat it for making that mental model and going through the process, which lets me really think about design choices, tradeoffs, and building that model. Sure, AI might polish up my thoughts in Confluence, but it’s not…designing a system for me.
This section is not to say that spec-driven design is a farce. I think it can work in the right context: a one-off system, or a system where you can get a grasp of things easily. But to go from rough idea to “here’s how everything will work in a complex system with lots of components, handoffs, moving parts” with a single prompt…there’s a reason system design should take time, because you need time to, and let me say it again, think about the nuance of everything.
The true productivity gains from AI come from trusting it, even when the companies (and training) says not to always trust it
You know when you open…literally any AI chatbot, and at the bottom of the window it says something along the lines of:
Claude is AI and can make mistakes. Please double-check responses.
Gemini is AI and can make mistakes.
ChatGPT is AI and can make mistakes.
But aren’t we supposed to be trusting agentic AI with writing our code, designing our systems, doing a lot of things for us…but it “can make mistakes”.
I get that this is a bravely naive take but hang in there with me for a second. Even on agentic AI loops, where bots are constantly self-checking themselves, writing unit tests, doing code review inline…they can still make mistakes. Sure, humans can make mistakes too. AI can be more precise if you give it enough feedback loops to self-correct itself.
But all this talk and I think we genuinely forgot that “AI can make mistakes”. I think there’s a lot of folks out there - especially junior engineers - who take what Claude gives them at surface level and don’t think for a moment to question if the bot is right.
I remember that when I was at university in my last semester, I did a fun experiment and I let GPT-3.5 basically take Geology for me. It was a filler class to check off the “please take some non-engineering classes” requirement on my graduation requirements (it honestly might not have been either and I just took it to take geology). This is a horrible admission to put on the internet (and I hope my degree is not rescinded), but it got a B. The one thing I constantly, constantly, had to do was ask GPT-3.5 “are you sure?”. And 50% of the time, it would change it’s answer. Then I asked it again, “are you sure?”, and then sometimes it would change it again. Sometimes it would go in loops and it was up to me if my rock knowledge was strong enough. Sometimes it thought it was sure but it got the wrong answer.
Even with AI to this day, sometimes, I have to ask it: “are you sure?”. Or, since we have harnesses that allow AI to browse the internet, I ask it to “cite your sources”. Then Claude or Gemini or whoever goes on the internet, finds that it hallucinated, and says “yes, I was wrong”. The rate at which this happens is still staggeringly high to this day.
Even with Claude Code, if I notice that it’s been thinking for a while, or is coming up with a comprehensive answer, there’s usually an “are you sure?” ask in there to make sure it’s coming up with a bug-free answer. Just from this, thinking times almost double.
If AI can’t produce a relatively simple answer for me without thinking to fact-check itself, then I’m not going to ever fully trust a fully agentic workflow.
AI that truly replaces humans might cost as much as an actual human (or take as long as a human)…maybe?
Admittedly, this section goes on a bit of a tangent of a theory that I’ve had about AI, it’s not proven, I am not a scientist or a scholar, but bare with me here.
For a while now I’ve had a hunch that an AI that is “as good as a human” might end up costing the same as paying a human. Especially with Fable 5 and Mythos 5, models with extremely high MTok costs, it kind of feels like we’re getting there somehow? I think Fable 5 and Mythos 5 on their own in a loop probably cost less than a human. But once you mix subagents in, commands like grill-me, using plan/execute loops, code review, things that are absolutely needed for long-running agents, then I think token costs absolutely skyrocket and maybe you’re looking at paying as much as a junior developer (on paper) to do the same job. And you have to consider that a human has to set up the agentic loop somewhere and keep an eye on it.
Yes, there’s administrative/benefits costs that come with hiring a human, so AI is “cheaper”, but meh, just some food for thought.
Another thing I’ve observed is that even if the AI does get the work done more cheaply (by using Sonnet or Opus), these models tend to make more mistakes in their loops and take absolutely ages to think about issues. One instance: I was implementing a GitHub Action at work, and these are notorious for having long feedback cycles because you kinda want to test the GitHub Action itself. Seems perfect for an agent, let it work in the background to self-correct the GitHub Action. But between planning, grilling, implementation, having to correct the agent, it took about 3 hours to complete end-to-end, which is about how long I would take to do the same task, assuming some help with codegen and troubleshooting from AI. Another instance I saw: Sonnet 4.6 took almost 35 minutes to identify a strange bug with modals in a legacy web application I have, and it’s very possible I might’ve found the answer faster. Yes, I could’ve multitasked and done something different…but I didn’t, because I had to still babysit the agent as it went off and added needless complexity instead of thinking about pivoting approaches.
In the last month with layoffs at major tech companies where the cited reason is AI, these companies seem to be regretting their choices and wish that humans were still in the loop. Last I recall Meta was wishing they didn’t lay everyone off.
A lot of companies are also instituting monthly budgets for AI usage by engineers, because running these agentic loops on production codebases costs a lot of money. I’ve had days where I’ve burned through $100 or more on Opus just to get tasks done. Uber instituted a $1,500/month/engineer spend limit for AI coding tools, and more companies are following suit. It sounds like the dream of these autonomous agentic loops using state of the art models to solve tricky problems on their own is gone…only accessible to those willing to pony up serious cash to basically get access to another engineer.
While AI has dramatically changed software engineering and is a productivity multiplier, I think the multiplier ratio is about 2-3x instead of the 10x that folks were originally envisioning without having to pay massive amounts of cash. Given the spend limit at my company, you’re basically forced to use Sonnet 4.6 for most tasks, and have some Opus days. I know some folks plan with Opus then implement with Sonnet, but sometimes I prefer implementing with Opus because it will catch itself quicker and pivot to a better plan without me having to babysit the agent. I guess it’s all a balance though.
The 90-90 rule applies with AI-generated code feels like 40-140+ sometimes
Tom Cargill once said “The first 90 percent of the code accounts for the first 90 percent of the development time. The remaining 10 percent of the code accounts for the other 90 percent of the development time.”
I think Tom was right back before AI existed. I still think this premise exists with AI generated code…but the ratio has shifted a lot further to the left. AI will get 90% of the way there much quicker than humans ever could. And perhaps for people who just want 90% of the way, that’s the real time saving from AI.
Getting the last 10% of the way is absolutely exhausting with AI. I find that Claude Code’s plan mode will generate a 90% plan very quickly and with reasonable accuracy, but once you actually dig into the plan and see how it jumped over lots of tiny (but important) details, then it’s a constant back and forth, ensuring no stone has gone unturned, that the chain of thought has included every little detail, and that I’ve asked Claude that “your implementation contains no bugs or obvious issues”. I know it’s like asking “make no mistakes”, but genuinely, I send this prompt to Claude and it comes back with “you know what, I didn’t think about that!”
To those who are saying I am not prompting correctly - see the nuance section above. To those who are saying “why not edit the plan myself”, see the context switching overhead section. This plan mode session isn’t happening in isolation, and to dive deep into the code, requiring a huge context switch and leaving the other agent to do nothing for 30 minutes arguably is less of a time savings if I had just…made the plan myself. That’s why I say it feels like 40-140+ sometimes.
Even when I’m not in plan mode, getting any AI bot to produce a final result that is well polished, clean, and bug-free takes an immense amount of effort compared to “clean enough” and “works for the most part”, when humans can at least try to lean towards the former of being polished & clean from the get-go.
Slop empowerment & design (did we forget about a simple no-frills design?)
Switching gears for a moment onto a rant. Because of AI, it seems like everyone and their dog has been empowered to make a frontend these days using AI. Whether it be a new service that AI made for them, or a one-off webpage, it seems like every single AI bot will make a website that looks polished and feels good, but is painfully obvious it’s “just another slop website”.
I loved this example I found on Hacker News, where a user had AI generate a race-to-270 tool in 8 different styles, and although they look different across the styles (and the Qt style is the only one that looks like a human could’ve made it), they all center back to a few common points:
Some huge call-out header that is painfully long at times
Always having a sub-header that painfully restates the obvious on the page, separated by little dot icons (or pills) adding zero value to the page
Gradients like the AI’s life depends on it
CAPITAL LETTERS ABSOLUTELY EVERYWHERE
Zero thought about usability or flexibility - it’s all about design
And for what? Did we forget that lovely frameworks like Mantine, MUI, even fucking Bootstrap exist? I understand that the first intuition these agents have is to try and make a professional looking website, but it ends up looking awful and lacks polish, requiring massive amounts of work.
A favorite benchmark of mine is to ask a LLM to generate a frontend for Beacon Hill Weather. I do this for a few reasons - mainly because a weather app has to, at the very least, present to you the current conditions, additional data, and a forecast (if you have it) in some structured way.
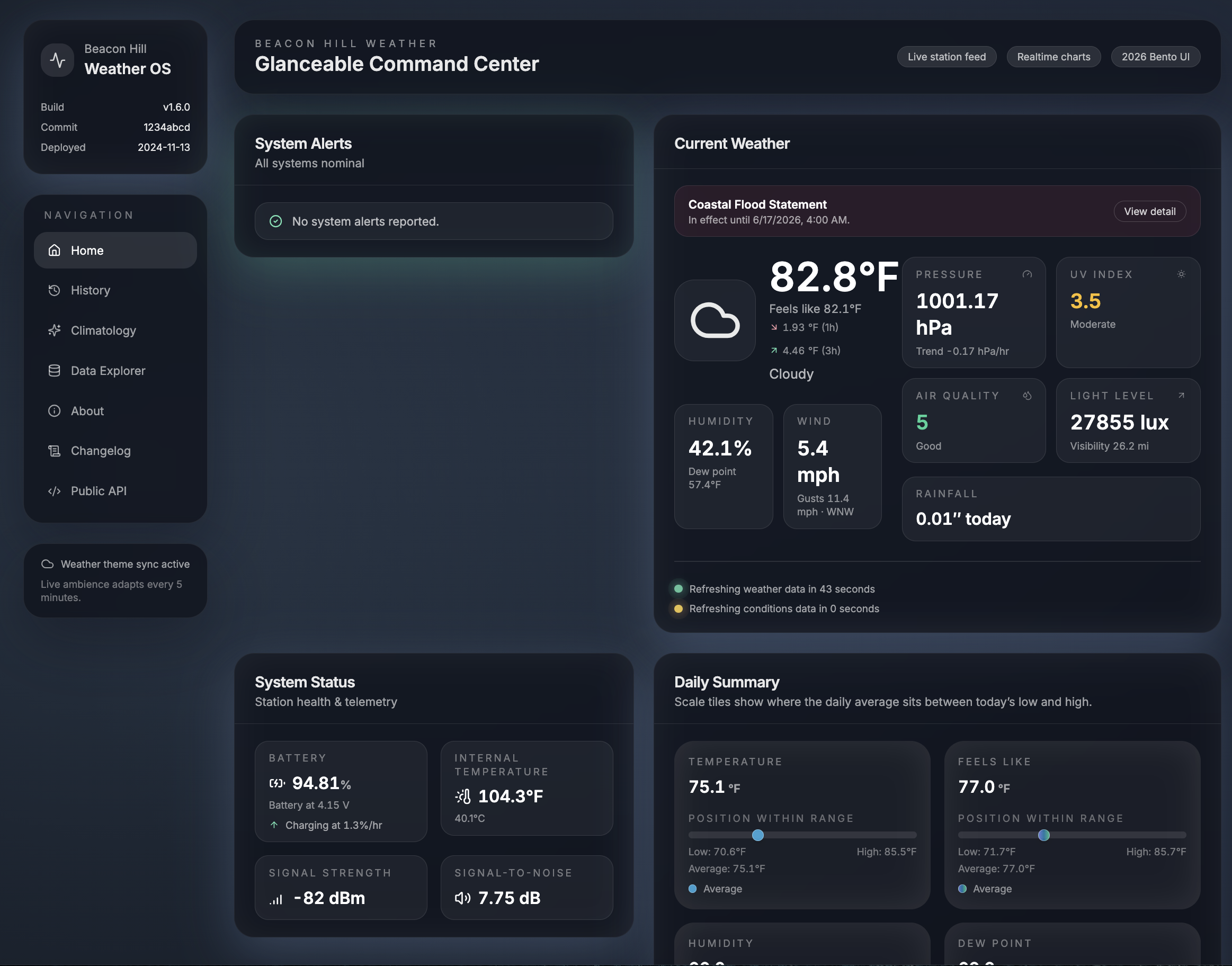
Back in March, I asked Codex 5.2 (or 5.3, I cannot remember) to have a shot at refactoring the existing Beacon Hill Weather website for me. It came back with this lovely design:
For reference, this is what the current frontend looks like, using MUI & Toolpad, which I designed in September 2024.
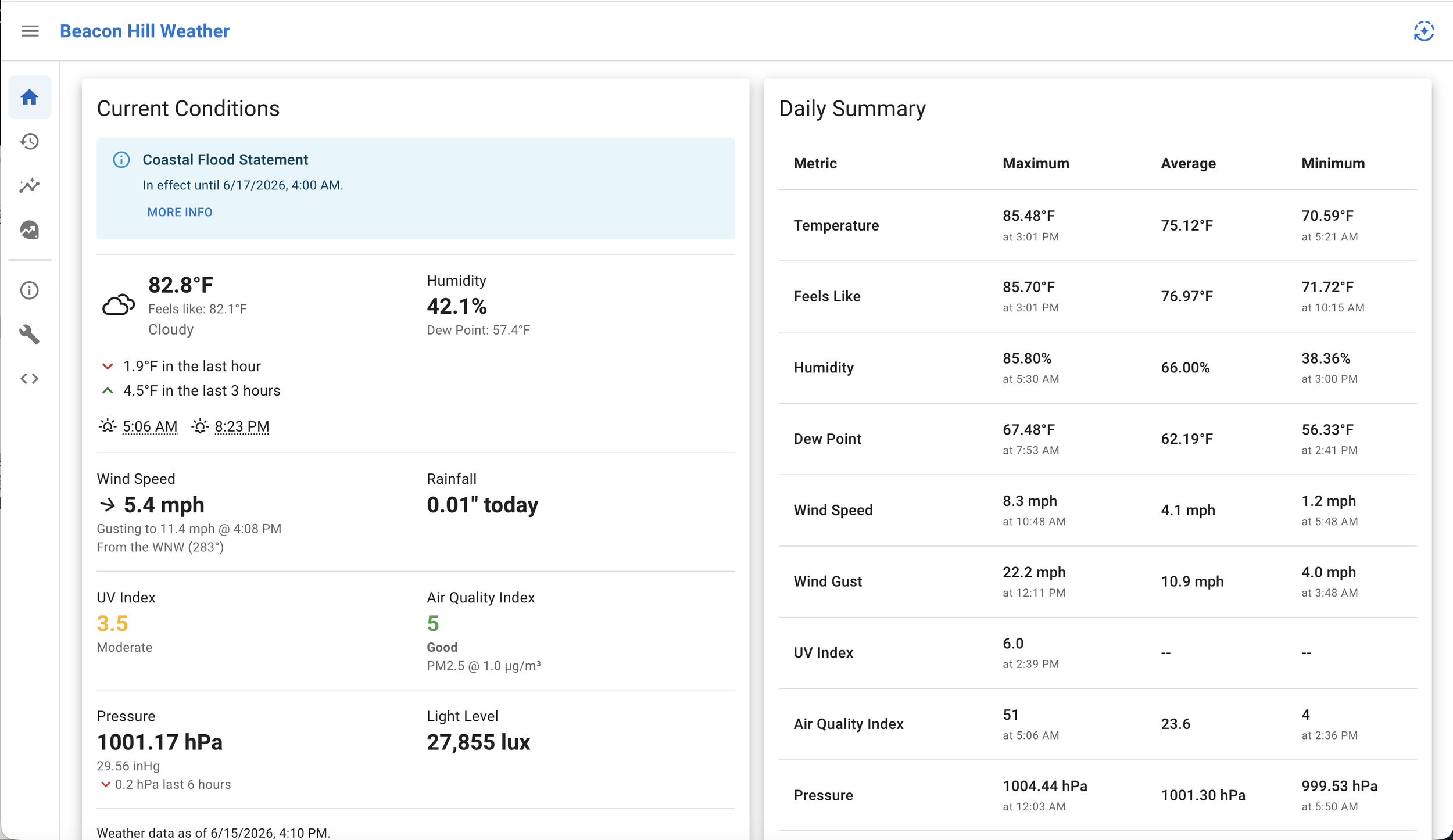
I mean, what the fuck. Genuinely, what the fuck. I know the current site doesn’t look “amazing” by modern standards, but it at least uses material design, is fast, and is usable.
Anyway, it’s kind of a bummer that LLMs are trained to make these slop-ass frontends 9 times out of 10 without major redirections. I have legacy projects that use Bootstrap 4.6 and Claude Code generally seems to handle it well, so it’s all very doable, but pomp over function, I suppose.
One last thing: trying to get LLMs to have any semblance of attention to detail in frontend design is a real test of patience. At some point I gave up with the Beacon Hill Weather frontend redo because there were so many glitches, so much to fix, so much prioritization for form over function, that it wasn’t worth it in the end. Yeah, sure, with enough coaxing I could have a nice gradient frontend for Beacon Hill Weather, but dare I say, the current frontend works just fine.
The funny bit about frameworks is that they have all the building blocks you need to make literally any website: it’s categorically less token spend because instead of whipping up alert blocks, cards, loaders, etc. from scratch, it’s included in the framework! And of course you can modify them to your liking (or not, which is what I also do!), but it’s so much better than trying to figure out what your LLM did with Tailwind behind the scenes.
I will likely be designing my own frontends for a long time to come.
The AI Bubble is real, but I don’t think it will “pop” like people imagine it will
Okay, so this is a bit of a tangent but just my thoughts about the state of the American (and honestly global economy) given that AI has surpassed the dotcom bubble by 10-20x. Please note that this is a political section with political views and skip this section if you are not interested.
I have a lot of concerns about how much AI is propping up our economy right now. I think AI is overvalued in my opinion - SpaceX bought Cursor for $60 billion as of recently, which, to be frank…is an agentic wrapper around VSCode. This is not to disparage the hard work that the folks at Cursor have done, but not even five years ago, an evaluation so high for such a young company would raise eyebrows around the industry. Anyway, this is a political opinion, so just beware of that and feel free to skip this section if you’re not interested.
It’s widely known that OpenAI and Anthropic are losing money, and that OpenAI delayed their IPO to 2027 for reasons around this (and the recent flop-ish of the SpaceX IPO). Is there an overindex around AI hype? I think so. Reality does seem to be crashing into place with how much it costs to run inference - Anthropic bills enterprise customers at API rates (which is not cheap!), most providers have switched away from fixed credit billing, and we’re even lucky to have ChatGPT/Anthropic’s subscription plans, because they lose money when you exceed 20% of your weekly usage limits. I think there’s further increases on token costs yet to come when the debt from datacenter buildouts & venture capital is realized at some point down the line.
We’ve also hit this sort of cliff in model performance as well - after the late 2025 gains, they’ve been very incremental into early 2026, and there’s been no huge progress since Opus 4.6 or GPT 5.4 seemingly. Yes, Fable 5 was impressive, but then the US government had to get in the way. Mythos 5? Too expensive for the rest of us, probably.
So, I think at some point, some part of the bubble will pop. I think we will see an inflection point where someone’s going to have to pay the actual cost of running these GPUs and training these models, and we might see the end of subscription plans, with API costs rising across the board. The issue is that, business across the world have started to depend on AI and now expect the velocity gains you get out of using AI on a daily basis. Developers on a daily basis reach an inflection point of using more AI daily compared to manual coding, and can’t think of going back to a pre-AI world, even if it ends up costing a fortune. So much time has been spent starting AI programs at companies across the globe, training employees how to use AI, setting up skills, workshops, and getting everyone onboarded, that a lot of places have probably gone past the sunk cost point, and more are blowing past it every day.
I think what we’ll end up seeing in a few years time (or even sooner) is increased inference costs leading to increased costs for business, leading them to bundle token costs as part of employee compensation packages, leading to increased costs for consumers, and little in the way of salary gains for employees (especially in software engineering). I don’t think Anthropic and OpenAI are going to go belly up, but reality is going to hit one way or another. Some companies will probably pull back on AI spending or drop it all together. Whether or not this leads to an overall recession or not…is up for debate, as we are firmly in a K-shaped economy and it will likely stay that way for a while, with the richest 10% of Americans continuing to make up a lot of spend in the economy. I just have a hunch this is going to lead to a rich keep getting richer program, the poor get poorer, and the middle class will continue to erode. AI is continuing to accelerate this and already the consumer tech segment has seen huge price increases because of AI - even Apple had to raise their prices.
In reality, I am quite unsure of how this all works out at the end. Like…very unsure.
Thoughts on RAM & component prices
One thing I despise about the current AI boom is that it has driven up the cost of consumer electronics by a margin that nobody was expecting. RAM and storage prices have ballooned exponentially, and a lot of people think this is a conspiracy to push cloud computing on end users. I think it’s not that, but the mechanisms of capitalism at play. There’s only so many memory fabs we can make in the world, and of course TSMC, Micron, etc. want to maximize profits by transitioning fab capacity to HBMs for extreme profit. I really wish that before AI took off that, we as a global society, said that we should keep a 50/50 split for HBMs to consumer memory, rather than the current 70/30 split we have today from what I recall.
Nonetheless - the cost increases have absolutely murdered the hobby electronics industry, and it is painful to look at my email inbox to see receipts from Micro Center to look at what I paid for components just a few years ago. AI is also continuing to murder the consumer electronics space - just after I published this post initially, Apple raised prices on their products, and many fabs reported that we’ll be seeing extraordinary RAM prices for years to come.
In 2024, I purchased a Pi 5 8 GB and 500 GB SSD from Micro Center to use as my GitLab server. It’s actually quite a stonking little combo and runs GitLab perfectly. Anyway: on May 19, 2024, the Pi 5 8 GB cost $79.99. The Corsair P3 Plus NVMe M.2 PCIe Gen 4x4 (note the spec) 500 GB SSD I bought on October 21, 2024 cost $40.99. Between the SSD Hat from Pimoroni, PoE Hat, and active cooler, the total BoM was around $150. An incredible deal!
If you want that same setup today, be prepared to pay $169.99 for the Pi 5 8 GB, and $99.99 for an Inland Gen4x4 500 GB SSD. After accessories, the BoM reaches approximately $300. That is no longer an incredible deal. That is a “what the actual fuck?” deal.
And of course, back in August 2023, I bought a 2 TB Samsung 970 Evo Plus NVMe M.2 PCIe Gen 3 x 4 SSD for the low low price of $79.99. The cheapest non-TLC SSD on Micro Center is now $429.99 for 2 TB. That is a 537% increase in price. Five hundred and thirty seven percent. Fuck, even on January 4th (literally 6 months ago), I bought a 1 TB Inland TN320 1 TB NVMe SSD for one of my servers - and this is a “pretty shitty” SSD by all standards - NVMe Gen 3 x 4, TLC, but it was $99.99. Now, it is $164.99.
Back in December, I knew that the PC market was about to implode, so for Christmas, I decided to build a new gaming PC at the very last possible minute with the help of some Micro Center build deals. In the bundle, 32 GB of DDR5 6000 RAM was $199, nowadays, this is $429 just by itself. I actually managed to snag a RTX 5070 Ti (with 16 GB of VRAM) at MSRP ($749), the cheapest 5070 Ti at Micro Center is $959. Fucking hell, I think even CPUs are getting more expensive? I didn’t even buy a SSD, I planned to reuse the 2 TB SSD from my old gaming PC, and that’s why I needed the Inland SSD to power one of my servers at the time.
Fuck man, even microSD cards for Raspberry Pis are wildly expensive. I bought a 2 pack of 64 GB SanDisk Ultra SD cards for $16.99 on November 22, 2025 and have some lying around. One of these cards is now $29.99. A two pack of 128 GB cards is $64.99. A pretty nice 200% increase.
Even crazier - Apple’s price increases! The company famous for having a rock-solid supply chain and insane margins on RAM premiums had to increase prices very recently. While this did not hit the iPhone - I suspect it will hit the iPhone sooner rather than later. iPads are now $150 more, the MacBook Neo is $100 more, and long gone is the $349 iPad.
MacBook Pros got the brunt of the impact - my personal M3 Max MBP - 36 GB RAM, 1 TB SSD, was $2,800 (with an education discount, in reality it MSRP’d for $3200) just two years ago. If I want to upgrade to a M5 Pro MBP with 48 GB RAM (to at least exceed what I have): $3599. M5 Max MBP with 36 GB RAM and 2 TB SSD? $4,499. To me, it is insane that tech is appreciating in value.
Unfortunately, this impacts everyone in the personal computing space - from business buying these laptops in bulk, to consumers looking to upgrade their computers, or unlucky people who have an old iPad or Mac, and need an upgrade now. The feedback loop that I mentioned above is starting to unfold with increased prices everywhere, but it’s currently a knock-on effect from how AI is increasing memory/storage prices in untold ways. It will be incredibly interesting to see the outlook on this in the future.
Long story short: capitalism sucks, and maybe as a society we shouldn’t have let this shit happen. We’re gonna be stuck in 8 GB laptop RAM purgatory for a while.
“The AI Privilege”, i.e. why aren’t we optimizing software anymore?
Speak of shitty amounts of RAM, AI loves to generate software that is not optimized if it’s not asked to do so. I swear, between the websites that any AI will generate, or literally any piece of software, it is never optimized to run efficiently on a device that is less than 2 years old, or consume a reasonable amount of RAM. Even Claude Code is a RAM hog - each instance uses almost 250 MB of RAM! Remember when we use to complain how much memory Chrome hogged up with ten tabs open? Well, for that multi-agent workflow, now you need 2.5 GB of RAM (I am aware of Claude Code’s built-in agent feature, but frankly, imo, it sucks compared to…just using tmux)
I think the funny part is that, knowing that Anthropic engineers have access to incredibly powerful models with nearly unlimited access, why can’t they ask Claude Code to rewrite Claude Code in a language like…Rust? Gone are the excuses of not wanting to use a language you don’t know, because the model can and will do it for you. Anyway, I’m looking forward to Claude Code consuming 500 MB of memory per session by the end of the year, mark my words. Is there a Polymarket bet I can place on this?
Shipping faster should not be the only metric. What happened to software quality?
A lot of the premise around AI is built around getting your teams to “ship software faster”. Feel free to take a look at any agentic AI coding software, or a new model release, and there will be a CTO or some higher-up exec preaching about how the time to build software has been minimized by some percentage, that velocity is up by some percentage, that more code is being written every single day. That’s great and all…but given how buggy and unpolished a lot of software has become in the last year, the trend of shipping faster also seems to, crazy enough, introduce bugs into your software much, much quicker. I’ve seen this at work, I’ve seen it in products I use daily, yeah, we’re getting cool features nobody asked for, but now some software is buggier than before.
If done right, AI gives us an incredible opportunity to build software at a relatively normal (or slightly accelerated) pace to before AI, but then have tons of time in the world to optimize the software, ensure it is rigorously tested, find edge cases and patch them, and do more than humans ever could without AI. I say, let’s ship a little slower so we can spend more time optimizing and understanding the software we have. It turns out that if you ship a quality product, people tend to trust it more and it puts your company in good graces! Personally, I wish we went this way
I still want to learn Swift and build iOS apps, but I refuse to use a LLM
For the longest time, I’ve wanted to build an app for Beacon Hill Weather in Swift/SwiftUI so I can learn iOS app development. As a stretch goal, I could get a complication for my watch that uses data from my weather station if I’m nearby, or from WeatherKit otherwise. I have a very small amount of native iOS app experience, I’ve used React Native before, but I want to use pure Swift.
I wouldn’t want all the features of the frontend in the app, graphs are painful on mobile devices to say the least, but something like the current conditions, daily summary, maybe a daily graph, and a way to view climatology & daily history. Probably 50-60% of the feature set that exists on the website. A modern LLM, even Sonnet 4.6, could code this app in an hour if I tasked it to. By the end of the night, I could have an app that could be published on the App Store if I really wanted to.
But I refuse. I refuse to do that. I grew up coding where part of learning a new language is the struggle. The slow, accumulated lessons, the trial and failure, reading guides, getting acquainted with a new framework - you bypass this entirely with a LLM. It feels like cheating to let a LLM code this app for me.
As I mentioned earlier, trying to learn and code like it’s 2023 is incredibly hard. Stack Overflow has seen a noticeable decline in quality over the last 2 years, and attempting not to reach out for a LLM to get me unstuck from a hard problem is like trying to be sober from cocaine even though the cocaine is across the room. I’m gonna want a hit, then another hit, and then before I know it, I haven’t learned anything and the LLM just built my app for me. Maybe that’s a self-control issue for myself to bridge, though. And absolutely - I could use the LLM as a building tool where I learn concepts through it - but nothing truly beats reading the documentation right from the source. I still remember little nuances and tricks from many libraries and Python itself, because as you read the documentation, you pick up on little nuggets of information
AI makes it so easy to not want to learn anything and delegate your brain and thought process to it, but AI is so infuriatingly hard to quit.
Are my thoughts even valid if AI is here to stay?
I ask myself this question at the end of this essay because it seems like AI is here to stay and we have to live with the consequences of it. I don’t think we’re going back to a world before AI whatsoever, especially at work. The velocity gains are too hard to ignore, it plays into capitalism too well. There will be exceptions at some companies, but the large majority of software engineering companies hit the inflection point either late last year or early this year, and I expect more to follow suit through 2026.
I have deep concerns about AI. I think a lot of people have similar concerns who are in a similar position have concerns. Middle management probably has concerns too, but the orders come from top down, and what’s the solution, reduce our velocity? Oh wait, we just laid off 10% of people this year for AI efficiency gains…better get those efficiency gains and ship more. It’s always do more with less, that’s just how companies work, and unfortunately, AI has given management a very powerful tool to “do more with less”, at least on the surface.
But alas, I am an IC engineer at level 2 with not much say, and I definitely do not set company goals, and I definitely didn’t promise a C-suite velocity gains with agentic coding. Also, my salary is <$300k, so clearly I am not paid enough to have an opinion that matters anyway.
A eulogy to the craft of Software Engineering
Ironically enough, I asked Claude to review the final version of this document. In the bit of back and forth in this conversation, it landed on a point about this article that I’d been dancing around but never hit. It was a euology to the actual craft of Software Engineering.
Folks who have a deep passion for their craft love the craft because it changes them as a person, and software engineering is no different. For every struggle, for every head-banging evening where you spent hours reading documentation, scouring Stack Overflow for answers, once you found an answer, it changed you as a person. You learned something new, you gained a better idea of system design, and most of all, you were proud of yourself.
Every one of my projects on my website was made substantially without AI, barring the Eiffel Tower Control frontend. Every one of these projects changed me as a person, fundamentally, and for every project, I can tell you exactly how it changed me.
Lesburu Analytics was a love-letter to myself because I had gotten through a break up and wanted to cheer myself up. I put all my energy and time that I could into that project in 4 months, learning many new subject topics: cellular connectivity, GPS modules, SQLite (and much more) - all of these lessons changed my perspective on software engineering, how to build reliable systems, and directly influenced the design of Beacon Hill Weather and future projects. And on a personal level, the satisfaction of getting a feature working after a long night of development was a high that I absolutely loved to chase.
Beacon Hill Weather is the true story of pride and resilience and refining my craft. I mean - who spends a year building your own weather station? But even in the pride of Beacon Hill Weather - a lot of the code behind the snow depth measurement functionality was written with the assistance of AI. Sure, I learned quite a bit about how to denoise measurements with buffer algorithms, but if I had to brute-force this problem without AI, I think I would’ve learned a lot more.
OctoCam was my first complex system I ever built, with 3 discrete systems running in parallel. Was it a mess? Absolutely. But having that first messy project taught me so many lessons about how (and how not) to design APIs and backend systems, or how to make OctoCam resilient to many, many, many types of errors. It taught me that in software engineering, you really can’t trust anything to build a reliable system, through years of…shit breaking randomly. NTP syncs breaking, having to infer sunset times from previous data, how not to bootloop your auto-reboot system, etc etc. But the knowledge I gained from building OctoCam is something I carry around with me every day, it is baked into how I operate as an engineer. AI just…engineers around that for you, adding these edge cases without you thinking about it. Or, it doesn’t, and you don’t understand why the system is breaking the way it is. You’re never taught about how to handle these odd issues because you never got to fix it yourself, or you had to outsource that thinking to AI.
I think about the last few months at work, where I’ve been exclusively using AI. Sure, I’ve absolutely been learning new things. But it’s at such a high level. Part of manually writing code was accumulating a wealth of ways on how to write code well, understanding the system I wrote at such a deep and intimate level (so deep that if something went wrong, I knew where to look 9 times out of 10!), finding ways to optimize your system, or maybe ripping out a chunk of code and finding a new way to do…something. Reading documentation was, dare I say it, fun, because I always found nuggets of information that were useful to me when reading it. Always thinking about “is there a way that I can do this better?”. And just from a project existing for a long time forward, running into issue after issue that advises the foresight you get as an engineer later in life. It all snowballed into building an intuition of what good code looked like, how good software was designed, debugged, built, and maintained. All of that is just…gone now that AI exists. AI isn’t motivated to give you little nuggets of information that may or may not be useful to you later on, it just gives you the answer every single time. Sure, you can always prompt it to dig up some useful knowledge for later, or give you insights about what went wrong, but it was nice to not having to prompt my own brain to do that repeatedly. And as this post has discussed, and from personal experience, reading an insight section on a Claude Code output does not retain knowledge in the same way that experiencing that insight first-hand ever will do. It’s just a fact of life.
And I think we’re long past the point where we can get this craft in software engineering back, at least in the sense of work. And I think most people have transitioned to using AI in personal projects to some extent because they use it at work, they’re used to how it works, even though a true art of the craft is being lost in the transition to AI in our lives. At least, this is true for me. I lost a way of growing how you think and change as a person when you deeply understand code - something that is inherently deterministic, to a non-deterministic LLM we’re forced to interact with for velocity gains. Something that will spit out different answers every time you ask it, or take a different approach. Even if this non-deterministic LLM can help us articulate ideas a lot sharper, or find something we couldn’t easily find ourselves, it takes away that self-pride of having overcome a problem ourselves and putting the time and energy to deep-diving into a problem-solving process that is so high-level with AI.
This entire post is basically to say that I think in transitioning to AI, we lost the actual craft of software engineering. We lost a way of growing how you think and change as a person when you actually write code and build things. And I dearly miss that. Already having a quarter life crisis and haven’t even qualified for it.
Thanks for reading this article to the end. I’ve spent the better part of a week writing this, and even though it’s unpolished and roughly written, you now have an idea of what I think about AI. I’ve had these thoughts for a while and wanted to put them somewhere on the internet, to document either how much of a fool I am, or that maybe I have a point. I guess the future will tell us which way the jury swings on this.
Please like, share, and subscribe, and you cannot leave a comment because I turned Squarespace comments off (but feel free to use the contact page to send me an email with your thoughts!).